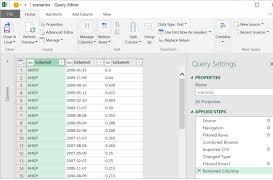
Data Mining or Importing Product Data from Excel https://docs.microsoft.com/en-us/power-bi/desktop-tutorial-analyzing-sales-data-from-excel-and-an-odata-feed Complete the following exercises with Power BI. Import Product Data from Excel Review for practice Make a screen print showing you complete import and data steps using the Excel spreadsheet.
Data Mining or Importing Product Data from Excel
Make 5 screen prints showing you created visualizations. Import Order Data from OData Feed https://docs.microsoft.com/en-us/power-bi/desktop-tutorial-analyzing-sales-data-from-excel-and-an-odata-feed Complete the steps to import an OData Feed into Power BI. Make 3 screen prints of your Data, Queries, and Relationships. Review the relationships between the tables for your analysis. In MS Word, explain the purpose of using OData. You will also need to discuss the Data and Relationship options with this OData model. What tables are connected to the Orders table?. Also, generate at least three new visuals showing valuable information for the measurements and fields. Explain what each of these visualizations represent in at least two paragraphs per output.
Evaluate Statistical Analysis Variables This week, you have learned about t-tests and ANOVA and will apply what you have learned in the evaluation of several research scenarios.
Evaluate Statistical Analysis Variables
For this task, you will read each research scenario and answer the questions regarding each one. Research Scenario 1 A researcher is interested in the effects of a new weight loss supplement. Participants in this double-blind study are randomly assigned to either a group that receives the new supplement or a group that receives a placebo. Participants are weighed before starting the program. After 6 weeks of taking either the new supplement or the placebo, participants return to the lab to be weighed. Provide the appropriate null and alternative hypotheses. Determine which type of analysis would be appropriate to answer this research question. Be specific and support your answer using the textbook or other course materials. Name the independent and dependent variables used in the analysis. What are the levels of the independent variable? Indicate the levels of measurement for each variable. Describe the Type I error for this study. Describe the Type II error for this study. Research Scenario 2 A researcher is interested in whether certain memory strategies help people to remember information. This researcher employs students from a local college, and then randomly assigns them to one of three groups—the visualization group, the mnemonic technique group, and the rote repetition group. Participants in each group receive an hour of instruction regarding how to use the particular technique to remember lists of words. After the instruction, all participants are presented with a list of 60 words that they are instructed to remember. The words are presented one-at-a-time on a computer screen. After the last word is presented, all participants are instructed to recall as many words as possible by writing them on a blank sheet of paper. All participants are given 10 minutes to recall the words. Provide the appropriate null and alternative hypotheses. Indicate which type of analysis would be appropriate to answer this research question. Be specific and support your answer using the textbook or other course materials. Name the independent and dependent variables used in the analysis. What are the levels of the independent variable? Indicate the levels of measurement for each variable. Describe the Type I error for this study. Describe the Type II error for this study Research Scenario 3 A local manufacturing company is interested in determining whether their employees are as happy with their jobs as other employees. The manufacturing company asked the workers, who volunteered to participate, to rate their happiness at work on a scale from 1 to 10 where 1 was not at all happy and 10 was extremely happy. The manufacturing company found that the mean happiness rating for their employees is 7.3. In the general population of workers in the United States, the mean happiness rating is 6. Provide the appropriate null and alternative hypotheses. Determine which type of analysis would be appropriate to answer this research question. Be specific. Please support your answer using the textbook or other course materials. Name the variables used in the analysis. What are the levels of measurement for each variable? Describe the Type I error for this study. Describe the Type II error for this study Length: 1-2 pages
The purpose of this assignment is for students to synthesize the concepts learned throughout the course. This assignment will provide students an opportunity to build critical thinking skills, develop businesses and organizations, and solve problems requiring data by compiling all pertinent information into one report.
Assignment Steps
Resources: Microsoft Excel®, Signature Assignment Databases, Signature Assignment Options, Part 3: Inferential Statistics
Scenario: Upon successful completion of the MBA program, say you work in the analytics department for a consulting company. Your assignment is to analyze one of the following databases:
Manufacturing
Hospital
Consumer Food
Financial
Select one of the databases based on the information in the Signature Assignment Options.
Provide a 1,600-word detailed, statistical report including the following:
Explain the context of the case
Provide a research foundation for the topic
Present graphs
Explain outliers
Prepare calculations
Conduct hypotheses tests
Discuss inferences you have made from the results
This assignment is broken down into four parts:
Part 1 – Preliminary Analysis
Part 2 – Examination of Descriptive Statistics
Part 3 – Examination of Inferential Statistics
Part 4 – Conclusion/Recommendations
Part 1 – Preliminary Analysis (3-4 paragraphs)
Generally, as a statistics consultant, you will be given a problem and data. At times, you may have to gather additional data. For this assignment, assume all the data is already gathered for you.
State the objective:
What are the questions you are trying to address?
Describe the population in the study clearly and in sufficient detail:
What is the sample?
Discuss the types of data and variables:
Are the data quantitative or qualitative?
What are levels of measurement for the data?
Part 2 – Descriptive Statistics (3-4 paragraphs)
Examine the given data.
Present the descriptive statistics (mean, median, mode, range, standard deviation, variance, CV, and five-number summary).
Identify any outliers in the data.
Present any graphs or charts you think are appropriate for the data.
Note: Ideally, we want to assess the conditions of normality too. However, for the purpose of this exercise, assume data is drawn from normal populations.
Part 3 – Inferential Statistics (2-3 paragraphs)
Use the Part 3: Inferential Statistics document.
Create (formulate) hypotheses
Run formal hypothesis tests
Make decisions. Your decisions should be stated in non-technical terms.
Hint: A final conclusion saying “reject the null hypothesis” by itself without explanation is basically worthless to those who hired you. Similarly, stating the conclusion is false or rejected is not sufficient.
Part 4 – Conclusion and Recommendations (1-2 paragraphs)
Include the following:
What are your conclusions?
What do you infer from the statistical analysis?
State the interpretations in non-technical terms.
What information might lead to a different conclusion?
Are there any variables missing?
What additional information would be valuable to help draw a more certain conclusion?
Format your assignment consistent with APA format.
We can write this or a similar paper for you! Simply fill the order form!
The analysis section should include the following sections:
1- Model Building: Explain your model in terms of the “cause and effect” i.e. clarify the dependent and the independent variables in your model. State and explain your hypothesis (theory) about a possible relationship between your dependent and the independent variables i.e. the type and the direction of the relationship between these variables should be explained. Example “there is a significant direct (or indirect) linear relationship between Var1 and Var2”. If you wanted to develop a multi-variable model, what other factors you would have included in your model. Explain the determination of the independent and the dependent variable in your model.
2- Visualization Step: Develop a scatter diagram and conclude if there appears to be a linear or a non-linear relationship between your variables.
3- Estimation Step: Estimate the regression line. Calculate and INTERPRET the estimated slope Calculate and INTERPRET the estimated intercept.
4- Goodness of Fit: Calculate the coefficient of determination and comment on the goodness of fit. Interpret your finding.
5- Strength of linear relationship: Calculate and INTERPRET the estimated correlation coefficient. Comment on the measure of strength of the linear relationship.
6- Test of the Strength: Test the significance of the strength of linear relationship between the two variables at 1% and then at 10% level of significance. Interpret your finding. Comment on the p-value.
7- Test of the Significance: Test the significance of the linear relationship between the two variables at 5%and then at 10% level of significance. Interpret your finding. Comment on the P-value.
8- Prediction Step: Use the estimated regression equation and forecast the value of Y based on a given value of X.
9- If you wanted to develop a multi-variable model, what other factors you would have included in your model
10- Develop a multivariate model of at least 2 independent variables. Compare to your earlier model, do you get more explanatory power? Comment on the coefficients and check the significance of the model as well as each independent variable.
We can write this or a similar paper for you! Simply fill the order form!
Nottingham, Quinton J. and James S. Hawkes, Discovering Business Statistics. Hawkes Learning Systems, 2013 (ISBN: 978-1-935782-87-2).
………………………………………………………………………………………
The following questions are intended to help you to master concepts covered in Module 1 Try to answer at least 5 of them. For those questions you cannot answer, describe the challenges that prevent you from doing so (do this for at least 2 questions). Each student is required to participate as this discussion counts for your attendance and gives you the opportunity to earn discussion credits.
1. What is the difference between population and sample?
2. What is the difference between parameter and statistic?
3. What is a frame?
4. Is a census different from a survey?
5. What is the difference between descriptive statistics and inferential statistics?
6. Why is it crucial to assess the quality of measurements and data?
7. What are the three questions we ask to determine whether we have good or bad quality measurements and data?
8. What are the 2 essential questions involved in developing a suitable measurement?
9. List the 4 steps of the scientific method.
10. What is the confounding variable and why a researcher must be more concerned by the presence of such variable when conducting a statistical analysis?
11. What is the role of data in decision making process?
12. What is fuzzy measurements and what types of challenges it is associated with?
13. What are the 2 types of methods of collecting data?
14. What is the difference between explanatory variable and response variable?
15. What are the differences between comparative experiments and before and after study experiments; and between Placebo Effects and Double-Blind-Studies?
………………………………………………………………………………………..
– Also, I will send you two of my classmates discussions to discuss with them.
– Write with easy simple words.
– I am an international male student.
– Please note that Professor is too serious about Plagiarism so please make it different.
We can write this or a similar paper for you! Simply fill the order form!
Before beginning this assignment, you should thoroughly review PowerPoint Presentation Creation; Enhancing Presentations with Pictures, Transitions, Objects, Backgrounds, and SmartArt from your course textbook, Go! All in one: Computer concepts and applications
For this assignment you will use Microsoft PowerPoint to create a presentation about a place to which you have traveled or would like to travel.
The presentation should include at least six slides that could describe the location, the method of travel, the qualities of the location that make it interesting or fun, the places you can visit, and any cultural activities in which you might like to participate.
Choose an appropriate theme, slide layouts, and pictures to format the presentation attractively.
Research the location and include properly cited (APA Style) material. Here is a great resource you can use to find information about places in the US and all over the world. (Be aware that the automatic citation generator for this site uses MLA style and not APA.)
Add (copy and paste) a chart or graph you can create in Microsoft Excel. This could be a travel budget.
Add (copy and paste) a table you can create in Microsoft Word. This could be a daily schedule.
Include a References slide at the end.
We can write this or a similar paper for you! Simply fill the order form!
1. Can linear and nonlinear optimization problems use the same approach to find a solution? For example, if the GRG algorithm is used to solve a nonlinear optimization problem, will it work to solve a linear optimization problem? Discuss whether or not the GRG algorithm will always find a corner point similar to the feasible-region approach.
2. Nonlinear optimization problems can have multiple solutions, and a solution can be local or global. Can there be multiple local solutions? Explain your answer. Can there be multiple global solutions? Explain our answer.
Use at least three (3) quality references Note: Wikipedia and other related websites do not qualify as academic resources.
We can write this or a similar paper for you! Simply fill the order form!
Choose a research question of interest to you. Gather information from a sample and draw conclusions. For example: investigate the timeliness of the Mira Mesa bus system. Another example: Spend time in your neighborhood grocery store at different times of day, measuring length of time people wait for checkout, how many lines are available, etc.
Project overview:
• Your options are to pursue a research question which will give you minimum of 50 data values.
• You will use descriptive statistics to analyze one and two variable results. Descriptive statistics includes the various charts and graphs that we studied as well as appropriate measures of center and spread (mean, median, percentiles, standard deviation, range, etc.).
• You will also use the tools of inferential statistics to decide on the possible validity of your results relative to a larger population. Inferential statistics include confidence intervals and tests of hypothesis. Plan to conduct two different tests of hypotheses and include at least one confidence interval.
• Your project must include BOTH descriptive and inferential statistics.
We can write this or a similar paper for you! Simply fill the order form!
Demonstrate an understanding of C++ programming concepts by completing the following:
1. Program: Create a C++ program that will function as an Employee Salary Calculator. Obtain from the user:
1 .Double variables for
1. Standard Hours worked
2. Rate of Pay
3. Overtime Hours (if applicable)
2.Calculate appropriate pay for standard hours and overtime (1.5 x rate of pay).
3.Provide formatted output using the following methods
1. setw()
2. setprecision()
2. Store the values into three different variables. For each variable, create three integer pointers that point to each values. Display the contents of the variables and pointers. In your program, be sure to use the new operator and delete operators to manage dynamic memory.
3. Program Analysis: Given your program implementation, discuss and identify the possible security vulnerabilities that may exist. If present, discuss solutions to minimize the vulnerabilities. Discuss and identify possible problems that can result in errors when using formatted output. Your analysis should be 1-2 pages in length.
Submit the following components:
.Word document with appropriate screenshots of your program executing, program analysis responses, and source code in the Word file.
.Submit your .cpp source code file(s). If more than 1 file, submit a zip file.
We can write this or a similar paper for you! Simply fill the order form!
Analyze the 2014 California Gubernatorial election results.
Make an educated projection for the 2018 Gubernatorial election.
This year’s election 2018 will be a midterm election. Midterm elections happen every 4 years in-between presidential election years. During these election years, we elect 1/3 of the US Senate and the US House of Representatives and state and local level public servants. During the last midterm election (2014) California voter turnout was at 42% for the November general election. Of the 24.3 million eligible California voters, 17.8 million were registered to vote in 2014. In 2010 turnout was at roughly 60% during the midterm election. California’s population has stayed at roughly 38 million people over the last 5 years. In this upcoming election 2018 we will elect a Governor of California. In the 2014 Gubernatorial election, Jerry Brown(D) secured 60% of the vote while Neel Kashkari(R) captured 40%. This years race for the Governor is between Gavin Newsom (D) and John Cox (R).
Step 1: Make a pie chart in which you show the percent of the California population that elected Governor Brown in 2014.
Step 2: Looking at the registration trends table and public opinion poll, make a prediction about this years Gubernatorial election. If you were on Newsom’s election campaign staff, what would you tell him to do? If you were on Cox’s election campaign staff what would you tell him to do?
here is an example
Step1:
In 2010
total California pop = 37.5 million
eligible voter pop = 23.5 million
Registered to vote = 17.2 million
Turned out to vote = 10.3 million or 60% of registered
Voted for Jerry Brown = 5.4 million or 53.8% of vote
Voted for Meg Whitman= 4.1 million or 40.9% of vote
Pie chart of 2014 vote
Jerry Brown was elected by 14.4% of the total population of California.
*All Data collected from the Ca Secretary of State’s Statement of the Vote
Brown has consistently polled at 40+% throughout the campaign, where Whitman has struggled at an average of 35% throughout. The poll trend line for Whitman votes leading up to the election is decreasing, meaning she is not gaining any speed but loosing traction going into the election. Based solely upon the polling results, I predict that Brown will win the election. Obviously this isn’t accounting for their difference in political experience, name recognition, gender, or other factors. If I worked on Brown’s campaign I would encourage him to campaign in the flowing light/Whitman counties with large populations: San Diego, San Bernardino, and San Los Obispo. He should also spend time in light/Brown districts such as Napa, Solano, and San Joaquin. He should particularly canvas in neighborhoods with a high density of younger voters, women, and the working class. If I was working for Whitnam I would encourage her to campaign in the same counties, while concurrently providing negative campaign adds in those counties. In addition, Whitman should try to recruit former Governor Schwarzenegger to campaign with her throughout the southern portion of the state. Given the Republican base, Whitman should particularly encourage white men and women to turnout to vote.
We can write this or a similar paper for you! Simply fill the order form!