Candies multiculturalism has positive effects on minorities
How Candies multiculturalism has positive effects on minorities
You MUST write the argumentative essay base on the outline I provide.
What you should use:
one academic book/2 academic journal articles/1-2 semi academic (you research based on library workshop guide)
You must complete essay worksheets I give you for every reading to record important information about each reading. You then use them in your essay. ALL ESSAY SHEETS TO SUBMIT WITH ESSAY. COUNTS TOWARD YOUR MARK.
Have an argumentative title
Have a clear thesis statement that gives your main point and argument.
Use transition words and reporting verbs for organization
Type double-spaced
Use correct punctuation
Give 8-12 short in-text citations as quotation & paraphrases in APA
***Remember: this is Process-writing and you need to take all the steps to be able to compose a qualified essay. You are not supposed to get help except from me, Writing Centre Tutors or OLC tutors or Library ESL corner. You should keep a copy of your external sources and your notes in case I ask you to present them to support the originality of your work.
Steps to take:
1. Start to think about the topic and all the readings and discussions we have had
2. Have a rough outline of your essay in mind or paper (we will have outlining session in class)
3. Select parts of the readings that you like to use as support/example/ evidence to support your main idea,
4. Mark them in your textbook and essay worksheets
5. Choose and learn the specific vocabulary/terms you need to use in essay
6. Know about how to make a simple quotation and paraphrase with citation in APA. I will teach this.
Until then, we will work on different parts of essay writing and you have the chance to practice writing some parts of it in class.
Mid-term writing assignment gives you the chance to write some parts of the essay and receive feedback from me.
Writing Centre (Ross South 5th floor) provides tutoring on all parts of assignments. Visit it online and register.
This is a general topic and you can discuss any part of it in essay as long as it is argumentative. Make sure you mark the key words in topic to use in title and thesis statement.
An argumentative essay defend and supports one side (ex. negative side) but also refers to the opposite ideas.
TOPIC
Discuss and argue the effects of Canada’s multiculturalism on minorities: does it have negative effects for example on their identity; does it lead to stereotypes and isolation; or does it have positive impact to strengthen their understanding of self and others?
We can write this or a similar paper for you! Simply fill the order form!
The task in this paper is to analyze the communication that takes place in your life using communication theory. You can pick an event regarding the following: may be any of the following: a televised debate, ad campaign (e.g., magazine advertisement, television commercial, etc.), personal communication (i.e., a significant conversation you had with someone), an interpersonal relationship, a novel you’ve read, or newspaper. Just not movies or tv shows! please write at a sophomore college level thank you!
COMMUNICATION 300
Application Paper
The task in this paper is to analyze the communication that takes place in your life using communication theory. To really make sense of the concepts and theories that we learn in class, you must apply them to your own life and really see how they work. The goal of this assignment is to increase your familiarity working with communication theory and to analyze how well communication is explained by the theories we learn in this course.
General guidelines:
Your paper should be 7-8 pages in length, one inch margins, stapled, double-spaced, 12-point font size, Times New Roman). You do NOT need a title page. Use page numbers (upper right). Use proper grammar, spelling, etc. Points will be deducted for not observing the guidelines outlined in the paper. Upload your paper to D2L by the due date.
We can write this or a similar paper for you! Simply fill the order form!
Basic Quantitative Data Analysis and Research If you are afraid of numeric data and feel (correctly or incorrectly) that your math skills are not up to par, you may face this phase of research with some trepidation. It may help to know that your clinical knowledge and experience are as vital to data analysis as are your mathematical skills.
Basic Quantitative Data Analysis and Research
On the other hand, if you enjoy working with numeric data and feel prepared to do so, this will be like any other phase of research except that this phase requires a basic knowledge of statistical analysis and some computer skills. For more complex analysis you will need more advanced skills and/or a consultant in statistics.
Basic Quantitative Data Analysis and Research
In either case, this phase is one of discovery. It is exciting to finally see the results of your study:
ï Did the intervention work? Are participants who received it better off than they were before? How much better off? If they are not better off, why arenít they?
ï Was your hypothesis about the relationships of interest correct? If not, are there any clues why not? How strong is the relationship?
ï Were there any surprises? Unanticipated results that need an explanation?
ï Do the findings support the existing theory? Do they suggest a modification of the theory?
There are a few steps to take yet to obtain answers to these questions, but by the time you complete the data analysis, you will have some answers.
Beginning researchers usually need the guidance of an expert researcher or statistician to complete this phase adequately. Remember, however, that it is your study and that you have become the expert on your study topic. It is best to stay involved in the data analysis even if you cannot do it on your own. You need to understand what has been done and what the results mean. Analysis cannot be done mechanistically: the theory and meaning that underlie each measure must always be kept in mind and are essential to the interpretation of the results. Reed (1995) reminds us that ìData alone do not yield up the theory any more than brushes will produce a paintingî (p. 95).
A deliberate, thoughtful, step-by-step process for analyzing quantitative data is described in this chapter. The description is basic and does not require a high level of statistical skill.
Basic Quantitative Data Analysis and Research Data Cleaning
Now that all of the data have been entered into the database and the database has been imported into the analysis program (if you were using an external file), it is time to review it once more for any errors that could affect the outcomes of the analysis. The following are a few things to consider:
ï Look at the data matrix on screen or in the printout. Are any lines too short (truncated) or too long? Are there any symbols that should not be there? For example, review of a large (7500-subject) data matrix that had been imported into SAS revealed #### had been entered as a value for the length of stay variable for several people. On another variable, gender, which was coded 1 = male and 2 = female, one value entered was y. In the first case, the #### probably means that the data were missing; a check of the original data confirmed this and a period (.), which is a SAS convention for missing data, was used to replace the ####s. In the second case, they were probably a typo. This was also confirmed, and a 2 for a female was used to replace them.
ï Recheck the scoring of tests to be sure it was done correctly. Was reverse scoring done correctly? You can do a random check to verify this. Do not just look at the first few lines of data, but in the middle and at the end of the database as well.
ï Make sure the correct coding categories were used. For example, it is critical that each person receiving treatment 1 be coded as a member of treatment group 1. One way to double-check this is to compare a randomly selected number of participantsí treatment group membership codes with the treatment group assignment noted on the test packet and on your tracking sheet.
Another way to double-check is to compare the value on one variable with the value on another. For example, you can use the assignment of ID numbers to indicate treatment group: everyone in treatment group 1 has a 1000ñ1999 ID number; everyone in treatment group 2 has a 2000ñ2999 ID number; and so forth. Another example would be to compare the country of origin or language spoken with the indicated ethnic group membership. Each study will have different variables that can be cross-checked in this manner.
Basic Quantitative Data Analysis and Research
ï Look for outliers, any number (value) that is outside the expected range for a variable. For example, an age of 101 is possible; an age of 201 is not. If the maximum score on a scale is 60, then any value over that indicates an error, whether in scoring or in data entry. However, not every outlier is an error; some may be legitimate. For example, an adult weight of 425 may be a data entry error or it may be correct. Entries of this type should be checked before deleting them (Saracino, Jennings, & Hasse, 2013). To find outliers, you can look at the frequencies for each variable on screen or in a printout (if your database is not too large). Every variable needs to be checked, even if you have put limits on their range within the data entry programs.
ï While you are going through the previous steps, watch for the frequency of missing data, especially for a pattern in the missing data. Handling missing data at this phase of the study presents some challenges, which are discussed in the next section.
MISSING DATA
Sources
Data may be missing at the item level (some items are left unanswered), construct level (all questions about gastrointestinal problems are left blank), or person level (some participants were not retested) (Newman, 2014). There are a number of reasons why data may still be missing despite efforts to fill in as much as possible during data collection:
ï The participant may have declined to answer a question or take a particular test.
ï The participant withdrew, moved, became ill, or died.
ï An item or test was missed inadvertently.
ï Participant fatigue, agitation, or another negative response made it necessary to omit all or part of the data collection.
ï A participant deliberately omitted the test or item because he or she thought it was not applicable or did not understand the question.
ï Poor directions or poorly worded questions elicited no response or the wrong response. Here is an example:
Basic Quantitative Data Analysis and Research
We asked long-term care facility staff to rate nursing home resident rehospitalizations as avoidable or unavoidable. To our astonishment, only 3.7% were rated avoidable. Conversation with nursing staff explained this extremely low rate: the nursing staff ratings were focused on the time at which the decision to rehospitalize the resident was made. Later in the project, which was designed to reduce avoidable rehospitalization, staff began to recognize that events in the days prior to hospitalization (increasing dehydration, for example) or capability of staff (to start infusions or intervene with anxious families of dying patients, for example) should also be considered, and they began to see more rehospitalizations as avoidable.
ï The data were collected but missed during data entry. If the missing data can be retrieved from the original files, the problem is easy to resolve.
Once all of the above are done, however, the remaining missing data need to be evaluated in order to decide how to handle them (Cook & DeMets, 2008; Little & Rubin, 2007). The missing data can be categorized as one of the following:
ï Missing completely at random (MCAR): This means there is no discernable pattern as to where data are missing. If so, then loss of information is more of a concern than is bias in the results.
ï Missing at random (MAR): The missingness is rarely entirely random; it is more likely to have some reason or reasons behind it (Newman, 2014).
ï Missing not at random (MNAR): Is there a pattern to the missing data? Is it a systematic problem? If so, this may introduce a bias into the data and subsequent analysis (Hardy, Allure, & Studenski, 2009). Little and Rubin (1987) emphasize that these patterns cannot be ignored but must be evaluated. There may be valuable information in the pattern of missing data. For example, Voutilainen, Kvist, Sherwood, and Vehvil‰inen-Julkunen (2014) evaluated the 12,446 missing responses on a patient satisfaction scale (the Finnish Revised Humane Caring Scale) completed by 5283 adult patients from four Finnish hospitals. They found that item nonresponse was clearly not random. Thirty-seven percent (1959) of the responding patients were responsible for all of the missing data. On average, these patients were older than those who completed all of the items. They also found that those who had been inpatients were more likely to complete all of the items than were those who had been outpatients. The researchers note the importance of understanding how these nonresponses affect the outcomes of the analysis.
It is important to identify the reasons why data are missing. Feedback from participants and the observations of data collectors may provide valuable information regarding the reasons for missing data. Analysis of the data may also provide information about the source of bias. The following are examples of the types of bias that might be found through analysis of the data:
Basic Quantitative Data Analysis and Research
ï Tests of function such as the Independent Activities of Daily Living (IADLs) often ask the participant if he or she can prepare a meal or balance a checkbook. Many older married men do not know how to cook and so will answer ìnoî or skip the question even though they could prepare a meal if they were taught how to cook. Likewise, many older married women have let their spouses balance the checkbook and will answer ìnoî or skip the question about balancing a checkbook, although they could do it if taught.
ï Another IADL function item asked participants if they played games of skill. Analysis of responses found a significant difference between ethnic groups (European Americans, African Americans, Afro-Caribbeans, and Hispanic Americans) in the number of participants who left this question unanswered. Here are the differences (Tappen, Rosselli, & Engstrom, 2010):
Ethnic Group Percentage Who Never Did This Activity
African American 18%
Afro-Caribbean 23%
European American 15%
Hispanic American 9%
Items such as these need to be worded carefully to obtain the desired information. Do you want to know whether the person actually does this activity, whether the person could do it, or both?
These examples illustrate gender and ethnic group biases in the data that cannot be ignored. The participants with missing data were not necessarily unable to perform the task, although they did not perform the task. Replacing the missing data with the code for ìnot doneî could lead to the highly erroneous conclusion that more men than women were unable to function in the kitchen, more women than men were unable to do the simple math to balance a checkbook, and more African American and Afro-Caribbean people were unable to play games of skill. Instead, a very simple replacement of the missing data with the participantsí means on the remaining activities that they did perform or a calculation of their individual means on a smaller number of items that they did perform would have been a more reasonable approach. Further analysis of the results of using the participantsí means on other items suggested that it was acceptable in this instance. However, in many cases a more complex approach is advisable.
Basic Quantitative Data Analysis and Research Replacing Missing Values
It may seem best to drop any participant with missing data from the analysis. This is called complete case analysis (Vittinghoff et al., 2012). If only a few are missing data, this may not bias the results too much; however, if it was primarily men, for example, who would be dropped from the analysis, then the results may not accurately represent this gender. Or sicker, poorer patients may not return for follow-up visits, leading to the impression of more positive outcomes than really occurred. There are several ways to address the problem of missing data after your initial evaluation has been completed. None is perfect. Replacement of missing data with a value derived from existing information is called imputation. Alternative approaches include deletion with weighting of remaining cases and direct analysis of the incomplete data (Rubin & Little, 2002). Missing data may be confined primarily to a single variable such as incomeóthis is called a univariate pattern. Or it may be found in certain cases when participants have withdrawn from the study or refused to complete certain portions of itóthis is called unit nonresponse. Missing data may be systematic in these and other ways, or they may be missing completely at random, abbreviated as MCAR (Little & Rubin, 2007).
Little and Rubin (1987, p. 44) quote an earlier comment by Dempster and Rubin that is worth repeating:
The idea of imputation is both seductive and dangerous. It is seductive because it can lull the user into Ö believing that the data are complete Ö and it is dangerous because it lumps together situations where the problem . . can be legitimately handled in this way and situations where standard estimators applied to the real and imputed data have substantial biases.
With this caution in mind, we will proceed to consider some basic principles in handling missing data:
ï Some missing data cannot be replaced. For example, if the participantís age is missing, there is no birth date from which to calculate it, and age was not recorded at a previous data collection point, that information is permanently missing and imputation cannot be done.
ï Imputation uses existing information to estimate the missing values. With single-item scales such as the powerful and ubiquitous self-rating of health (ìFor your age would you say, in general, your health is excellent, good, fair, poor, or bad?î; Massey & Shapiro, 1982, p. 800), it is difficult to estimate the response that would have been selected by an individual participant. Missing items within a multi-item scale are more amenable to imputation.
ï The easiest (and most ìseductive and dangerousî) approach to replacing missing data is to use the groupís mean (average) on the item. The problem is that there is little foundation for assuming that a particular participantís rating would be average. Further, if you replace too many missing values with the average, the variability among participants may be drastically reduced, an undesirable situation that may lead to erroneous conclusions.
Basic Quantitative Data Analysis and Research
ï A somewhat more targeted and justifiable approach is to use the average of the individual participantís scores or ratings on the remaining items of a multi-item scale. For example, if an IADL scale has 25 items and 2 are missing, the average score on the 23 items can be used to fill in the 2 missing scores. This assumes that scores on individual items are highly related, which needs to be established because it is not always the case. (In fact, very highly correlated items on a scale are considered redundant and often deleted during scale development.)
ï Missing values may be estimated from values at previous time points. Again, this is based on the (often shaky) assumption that that particular score has not changed. In fact, one of the primary reasons to employ multiple data collection points is to detect change over time. In some clinical trials, the last observation carried forward (LOCF) approach is used (Phillips & Haudiquet, 2003; Vittinghoff et al., 2012). In this instance, the data from the previous testing time point are used to replace the missing data. There are many problems associated with this approach. It is based on the assumption that no outcomes of interest would have changed between testing times, a difficult assumption to support in many instances (Cook & DeMets, 2008). More complex approaches have been developed to avoid these problems.
ï Incomplete cases (participants) may be deleted, and the analysis may be done on those who completed the study. The problem with this approach is that the people who drop out are likely to differ from those who remain in important ways. Those who drop out may have had a disappointing response to the treatment being tested or they may be less persistent than those who completed. If, however, people were lost due to external circumstances unrelated to the study (a new job took them to another state, for example) then their loss may not affect the outcomes of the study.
ï An alternative is to weight comparable complete cases to compensate for those that are lost (Little & Rubin, 2007).
ï Complete observations (those without any missing data) may be used to fill in for those with missing data. In effect, those with complete data who match those with missing data on the characteristic of interest (the oldest, most severe asthma, highest weight or drug use, and so forth) are double or triple counted. This is a form of weighting responses. The approach is called inverse probability weighting (Vittinghoff et al., 2012).
ï There are several more complex calculations that may be made to estimate the values of the missing data. Instead of using the mean of othersí scores, a regression analysis may be used to predict the values of the missing scores. This is called regression imputation. Other formulas for estimating the values of missing data include maximum likelihood and multiple imputations (Duffy & Jacobsen, 2005; Little & Rubin, 2007).
Expectation maximization (EM) is an algorithm that uses a formula designed for random missing information (Little & Rubin, 2007, p. 114). The first step involves computing expected values. In the second step, the effect of substituting these values is evaluated using maximum likelihood, a method of estimation used in factor analysis and structural equation modeling in a series of iterations until convergence is achieved (Munro, 2005, p. 439).
Multiple imputation avoids some of the disadvantages of using single imputation. Instead of using a single set of replacement values, somewhere between two and five (even 10 in some cases) different sets of replacement values (repetitions) can be contrasted and combined to obtain the best set of estimates for the missing values (Duffy & Jacobsen, 2005; Little & Rubin, 2007).
VISUAL REPRESENTATIONS
Now that all of the data have been entered into a database, the database has been cleaned, and missing data are filled in or replaced as much as possible, you are ready to initiate the actual analysis of the data. If your work has been careful and thorough up to now, this phase should go relatively smoothly and more quickly than you might at first imagine. Informally, this first stage of analysis is called ìeyeballingî the data.
Basic Quantitative Data Analysis and Research
Many statisticians caution eager researchers not to skip this initial phase of analysis. Much of what is done here is not included in a final report or published article on your study, but it is a valuable first look at characteristics of the sample (the participants), the outcomes of the study, and the relationship between the two. This first look may suggest relationships that were not anticipated and may cause you to use some additional analyses not anticipated when the study was designed. In other words, this may be a stage of discovery as well as evaluation.
Actually, you began eyeballing the data during the previous steps directed toward finding errors and dealing with missing data. Now you will eyeball the data once more to look at the characteristics of the results on each variable and how the variables are related one to another.
Graphics capabilities differ considerably from one data analysis package to another, but most should be able to generate the simple visual representations discussed here.
There are many ways to visually represent data. We will look at a few basic ones: stem and leaf, box plots, bar and pie charts, and plots. Data from a sample of 150 students at an urban university who were majoring in nursing and psychology will be used for illustrative purposes.
Stem and Leaf
You may have to use a little imagination to actually see these representations as a stem and leaf, but this is often the first graphic studied. An example can be seen in Figure 19-1. This is a stem-and-leaf representation of a sample of college students whose average age was 27 years with a wide range of 18 to 61. The ìstemî represents the number of years the students have lived in the United States, which ranged from 4 to 56 years. The ìleafî represents the number of students (frequency) in each category, from 4 to 56. You can see that the largest number had been in the United States for 22 years. (This is the mode or most frequent value, by the way.)
Basic Quantitative Data Analysis and Research
Figure 19-1 Stem and leaf and box plot for years in the United States in a sample of college students.
You can also see that the numbers seem to cluster in the 14- to 28-year range and that there are more at the lower end of the stem (fewer years in the United States) than at the higher end. Why this imbalance? Knowledge of the sample explains it. This is a diverse group of college students including European American, African American, Hispanic American, and Afro-Caribbean students. A portion (not yet determined in this analysis) of the latter two groups was not born in the United States but came to the United States at various ages. This explains the imbalance to the lower end of the range of years in the United States. This is an important characteristic of this sample of college students.
Box Plots
A box plot is illustrated in Figure 19-1 to the right of the stem and leaf. The box plot also suggests an imbalance toward the lower end of the range. The horizontal line across the box indicates the median (middle value) or 50th percentile of this distribution. The top of the box is the 75th percentile (75% of the cases fall at or below this line), and the bottom is the 25th percentile (25% of the cases fall at or below this line). The dashed vertical line above and below indicate values that are not outliers. The zeros above this line from 44 to 56 years in the United States indicate outliers that lie outside (above or below) most of the distribution. The full length of the box represents the interquartile range (IQR), from the 25th to the 75th percentile, which constitutes the middle half of the distribution (Duffy & Jacobsen, 2005). A series of box plots (not shown) may be done to show differences in distribution among several groups; for example, they could be used to show the differences in years in the United States by ethnic group membership.
Bar Charts and Pie Charts
These charts are especially helpful in visualizing differences between several groups within a sample. The simplest bar and pie charts show the frequency (total number) within each group. For example, Figure 19-2 is a very simple pie chart that illustrates the proportion of the college student sample that is European American (26.75%), African American (17.20%), Hispanic American (28.03%), and Afro-Caribbean (28.03%). It is quickly apparent that the African American group is a little smaller than the other three groups, and there are a few less European Americans than there are Hispanic American and Afro-Caribbean students.
Basic Quantitative Data Analysis and Research
Figure 19-2 Pie chart showing proportion of each ethnic group within the sample.
The bar chart in Figure 19-3 illustrates a slightly more complex relationship between nominal data (ethnic group) and interval data (depression scores): the mean scores on the CES-D depression scale (Radloff, 1977). In this instance, you can see that the Hispanic American students have higher CES-D scores than the others…
We can write this or a similar paper for you! Simply fill the order form!
BMW’S ROAD TO HIGHER CUSTOMER SATISFACTION: JUST TELL ME WHAT YOU THINK!
Customer satisfaction and loyalty are critical elements in any successful marketing strategy, but they are essential when the product is purchased only once every few years. It was, therefore, of great concern to luxury automakers like Acura, Audi, and BMW when in 2014 their customer satisfaction scores all dropped below the average for the entire automobile industry.34 For years these companies had been gathering and using external primary data from their own surveys, and also relying on secondary data from sources like the American Consumer Satisfaction Index, yet satisfaction was falling. Assuming the luxury automakers were listening and responding to the data they received from existing research, it appeared the old modes of research were missing key insights. Management had a new research deliverable learn how we can improve customer satisfaction and a new research question what specific product attributes or service components are not satisfying our customers?
Questions for Consideration
1. Assuming BMW wants to learn more about what customers value in a luxury driving experience, and then make decisions based on that research, what kind(s) of market research would you recommend that might improve BMW’s understanding?
2. BMW is facing the classic quality- quantity -cost trade-off; when it seeks higher-quality information (represented by more questions), fewer responses are received or research costs are higher. Since BMW’s executives all have 25 to 30 years of experience in the automotive market, what would be the advantages and disadvantages of trusting their own experience versus spending more on market research?
3. When problems develop, like what BMW is experiencing in its research data gathering, a new, often technological solution is developed to address the issue. What might be some innovative ways to approach gaining both statistical significance (through higher response rate) and deeper context (through open-ended qualitative data)?
We can write this or a similar paper for you! Simply fill the order form!
The Absolutely True Diary of a Part-Time Indian Novel
The Absolutely True Diary of a Part-Time Indian Novel
You can search for “Indian Horse” on the Learn360 app under “Media” on the BYOD page.
“The Secret Path” can be found on the Curio app on the BYOD page.
The summative for this unit will involve making connections between the films and the novel we studied.
Your assignment must follow these formatting requirements:
Be typed, double spaced, using Times New Roman font (size 12), with one-inch margins on all sides; citations and references must follow APA or school-specific format. Check with your professor for any additional instructions.
Include a cover page containing the title of the assignment, the student’s name, the professor’s name, the course title, and the date. The cover page and the reference page are not included in the required assignment page length.
We can write this or a similar paper for you! Simply fill the order form!
International leadership and management Case Study
Your abilities in international management have been recognized, and your consulting assistance has been requested. The company Quasimoto Enterprises has been approached by a reputed Chinese firm that wants exclusive production and selling rights for one of its new high-tech products. The company has been looking for a strategic partner for the production of this product to reduce costs. Hence, Quasimoto Enterprises is very interested in exploring the possibility of developing relationships with this Chinese firm. This deal is very critical to growth of Quasimoto in the international market. Both parties are anxious and preparing for their first meeting in a month’s time to move this deal forward. This is the first time Quasimoto is doing business with China, and this is also the case with the Chinese firm.
We can write this or a similar paper for you! Simply fill the order form!
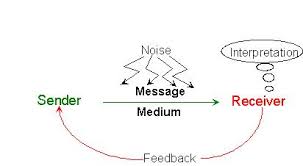
How do the nervous and endocrine systems work together to maintain homeostasis?
How do the nervous and endocrine systems work together to maintain homeostasis?
Use your existing knowledge and research from the material that you have learned this quarter to describe how these two systems work together to maintain homeostasis. Be sure to include relevant details from both systems and include multiple examples of how homeostasis is achieved.
Minimum of 2 double spaced pages and no need to go over 3 double spaced pages as a maximum (you may, but to keep this project reasonable, please adjust level of detail as to not overwork yourself).
Your assignment must follow these formatting requirements:
Be typed, double spaced, using Times New Roman font (size 12), with one-inch margins on all sides; citations and references must follow APA or school-specific format. Check with your professor for any additional instructions.
Include a cover page containing the title of the assignment, the student’s name, the professor’s name, the course title, and the date. The cover page and the reference page are not included in the required assignment page length.
We can write this or a similar paper for you! Simply fill the order form!
Case Contributor: Chad Gruhl, Ph.D., Metropolitan State University of Denver
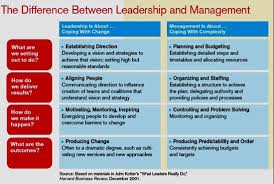
Title: Leadership: Who’s the real leader?
Purpose:
To understand the difference between leadership and management
To determine the role of a manager
To determine the need for a leader
To assess when leadership is necessary
To assess the qualities of a leader and a manager
Company Background
The Vision Hotel is a large convention hotel and meeting complex with 1500 rooms and 300,000 square feet of banquet space in downtown Denver, Colorado. The London Hotel is slightly smaller with 1200 rooms and around 250,000 square feet of banquet space. Both hotels are near each other; both opened around the same time, and both have been open for nearly two years.
Both hotels have experienced an occupancy rate of around 80 percent yearly, which is above the industry averages. However, the Vision’s occupancies have been dropping over the past three months.
Industry
The Colorado hotel industry in general has been booming for the past two years. Employers in the industry, however, face the difficulty of filling all the positions available because there are not enough applicants. This is a huge challenge for other large hotel markets around the country as well. Most hotels end up burning out their employees because they are short staffed and employees end up doing twice the work.
Case
Adam Parson is the General Manager at the Vision Hotel. He has been there since the opening of the property. Adam is a nice person according to most of hisemployees, who refer to him as Mr. Parson, but they usually donít see him much even though he typically works 13 hours a day, 6 days a week. Adam spends most of his time in his office working on budgets and in meetings with his executive managers and department heads. He was transferred to this property from the company’s largest hotel in New York City because of his apparent management skills. The company has been very happy with him over the past five years because he has brought more money to the bottom line than any other general manager in their hotel portfolio, which includes 40 hotels across the country.
Adam spends a lot of time watching the industry trends, which leads him to making accurate predictions of future changes in the industry. For example, he predicted 10 years ago that many hotels would eliminate the minibar in guestrooms. His prediction came from the fact that industry revenues from the minibars had been continuously dropping for four straight years. At the same time, guests had been complaining about the high prices of the minibar products. His prediction was right on target. Over 13 years ago, Adam took out the minibars in his hotel and ended up saving money from labor and product costs. He knew what was coming and knew how to save money. This is an example of being a good transformational leader. Adam reacted to the industry trends before losing revenue and transformed the situation to a positive one, which also indicates great vision on his part.
Last year, Adam received the General Manager of the Year Award for the most profitable hotel in the system. However, he has been concerned about the turnover rate of employees over the past two years of operation in Denver. Adam knows it is very expensive to hire and train new employees. As a consequence, he has been pressuring his Human Resources Director for the past three months about the rising costs of turnover. Known to be a planner, Adam wants to see a plan from his HR Director on how this will be corrected soon, as well as in the future.
Adam is also upset that the occupancies for his hotel have been dropping compared to the competition. He has been having numerous meetings on the subject with the Director of Sales. He was so upset during one meeting that he slammed his fist down on the board table and told the Director to get their [sic] act together and bring in more business.
Kim Itasca is the General Manager at the London Hotel. Kim has been managing the property for the last 12 months. Before she started working at the London Hotel, problems included employee stealing, a turnover rate that was well over the industry average, and an occupancy rate that was the lowest of the large hotels downtown. Kim works about 10 hours a day, usually 6 days a week. Kim prefers not to have a lot of meetings with her management staff because she believes that managers need to be out with their employees and customers. Kim takes what she calls tours of the property every two hours. Each tour takes about two hours. When she walks the property, she stops and talks to as many employees as possible asking them about their day, their families, and how they like working at the London. She wishes she could learn all the names of her 900 employees, but she has learned only about half so far.
Kim usually spends one third of her day in the office going over paperwork, looking over revenue and cost reports, and answering her e-mails. She would prefer to be on the floor with here employees, but she recognizes that administrative work is also a part of her job. However, she knows that this is not the most important part of her job. Making sure her employees are happy is the most important part.
Kim encourages her employees to take care of the customers no matter what. She even went as far as telling her employees to spend up to $1,000 per customer situation to make a situation right for a customer. This includes comping hotel nights, meals, transportation, or whatever the employee feels is necessary to turn a bad situation into a good one. Kim is all about ensuring that her employees (including managers) are successful.
Over the past year, the employee turnover rate at the London Hotel has dropped by 10 percentage points. The Security Director has reported that theft has dropped dramatically, and employees overall appear to be much happier in their jobs than ever before.
What are some of the leadership skills of Adam? Of Kim? Who is the better leader? Why?
Respond in the form or a well-developed paragraph, supported by cited references to our text.
We can write this or a similar paper for you! Simply fill the order form!
Essay that supports or refutes Mr.Cohen’s claims on our president Donald trump if hes a racist , liar , conman, cheat must provide proof in claims
Recent as 3/6/19 , Micheal Cohen testified before congress and said his former boss our president Donald trump is a racist and liar, conman, cheat. Take special care with evidence on claims. If the writer wants to refutes a claim, then evidence must fall into one of the five types of accepted evidence LEGAL , SCIENTIFIC, EXPERIENTAL, DOCUMENTARY, and STATISTICAL
We can write this or a similar paper for you! Simply fill the order form!