Apple is consistently rated as one of the world’s most innovative companies.What evidence to this effect do you see on the website?How has Apple translated innovation into a major strength?
Most of Apple’s products carry a premium price relative to those of the competition.Does Apple’s strengths in innovation overcome its weakness in price competitiveness?Explain.
Your assignment must follow these formatting requirements:
Be typed, double spaced, using Times New Roman font (size 12), with one-inch margins on all sides; citations and references must follow APA or school-specific format. Check with your professor for any additional instructions.
Include a cover page containing the title of the assignment, the student’s name, the professor’s name, the course title, and the date. The cover page and the reference page are not included in the required assignment page length
We can write this or a similar paper for you! Simply fill the order form!
**Definition:** The **power** of a statistical test is the probability the test correctly rejects the null hypothesis when it is indeed false.
Statistical Computing Assignment Paper
1. Let’s explore the `rnorm` function. The `rnorm()` function in R randomly generates data from a normal distribution with a specified mean and a specified standard deviation. Recall we saw the exact equation of the probability distribution function in the notes. The r in `rnorm` stands for “random.” The data will be randomly drawn based on the probabilities dictated by the probability distribution function.
a. Use the `set.seed()` function with a seed number of your choosing. Then complete the following: Use `rnorm(500)` and draw a histogram using `ggplot2` tools of the resulting data values. Enter your code in the space provided below so that when you **knit** this document it will show the code and the histogram.
“`{r problem1a}
“`
b. Use `rnorm(500)` again and draw a histogram using base tools of the resulting data values. Note: You do not need to use the `set.seed()` function again. Enter the code in the space provided below.
“`{r problem1b}
#Enter your code here.
“`
c. Write a few sentences to describe your histograms in parts a) and b). Also, explain What you think the 500 in the code represents. Type our answers below in plain text:
TYPE YOUR ANSWER HERE!
d. Based on a) and b), what do you think the default mean is for the `rnorm` function? How did the graphs inform your answer? Type your answers below.
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
e. Do you know what the default standard deviation is? How did you determine this?
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
f. Use `rnorm(500,100,5)` and draw a histogram (`base` or `ggplot2`) of the resulting data values. Report your code in the space provided below.
“`{r problem1f}
#Enter your code here.
“`
g. Use `rnorm(500,100,5)` again and draw a histogram (`base` or `ggplot2`) of the resulting data values. Report your code in the space provided below.
“`{r problem1g}
#Enter your code here.
Statistical Computing Assignment Paper
h. Based on f) and g), what does the second argument (the 100) of the `rnorm` function do? How did the graphs provide evidence of this for you?
TYPE YOUR ANSWERS HERE IN PLAIN TEXT:
i. What does the third argument (the 5) of the `rnorm` function do?
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
j. Generate 1000 observations from the F distribution with 5 numerator degrees of freedom and 10 denominator degrees of freedom. Draw a histogram (`base` or `ggplot2`) of the data values.
“`{r problem1j}
#Enter your code here.
“`
k. Write a few sentences to describe the histogram you generated in part j.
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
*Now that you have an understanding of how the `rnorm` function works, complete the following problems. These items go together to investigate the statistical concept of power.*
2. Create two scalars named `rows` and `samplesize` with the values of 10 and 3, respectively. (We will later change these values to 1000 and 30, but while you are working on getting all of your code to run, these smaller values will allow you to print objects and view them to investigate what is going on).
“`{r problem2}
#Enter your code here.
“`
3. Use the `set.seed(1000)` function so that we all are randomly generating from the same starting point.
“`{r problem3}
#Enter your code here.
“`
4. Use the `rnorm()` function in R in order to randomly generate data from a normal distribution with a mean of 100 and a standard deviation of 5. You should generate enough values to fill in a matrix with the number of rows and the number of columns given by the objects `rows` and `samplesize` that you created in #2. You should not retype their values. Instead, reference the objects so that later you can make the change once in the code to explore other rows and sample size options.
“`{r problem4}
#Enter your code here.
“`
5. Create a matrix of the data values you randomly generated in #4 that has the number of rows given by the scalar you created in #2. Also include code to print the matrix you created.
“`{r problem5}
#Enter your code here.
“`
6. Calculate the mean of each row of your matrix and store this information in an object called `mymeans`. Print the output. Answer the question that follows.
“`{r problem6}
#Enter your code here.
“`
What do you notice about the sample means from your samples and the mean of the normal distribution from which they were drawn?
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
7. Calculate the standard deviation of each row of your matrix and store this information in an object called `mysd`. Print the output. Answer the question that follows.
“`{r problem7}
#Enter your code here.
“`
What do you notice about the sample standard deviations from your samples and the standard deviation of the normal distribution from which they were drawn?
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
8. Suppose you planned to test the hypotheses of $H_0: \mu = 107$ vs. $Ha: \mu \neq 107$ in order to determine if the mean of the population from which your data is drawn is different from 107.
a. Question: What is the true mean of the population from which this data is drawn? Type your answer below in plain text.
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
b. Question: Therefore, what do you expect your p-value would look like (small or large)? Type your answer below in plain text.
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
c. Question: Therefore, what is the correct outcome of this test (reject the null or do not reject the null)? Type your answer below in plain text.
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
d. For this test, you would calculate the test statistic as $$t=\frac{\bar{x}-107}{s/\sqrt{n}}$$
Using the objects you created in #6 and #7 and knowing that you created an object in #2 called `samplesize`, which indicates the size of your sample, calculate this test statistic for every row of your data using R. You do not need the apply function, this is just a calculation involving vectors! Save your vector of test statistics in an object called `test.stat`. Be very careful with parentheses!! I would calculate the numerator and denominator separately and then divide if I were you! Your code should ultimately print the object `test.stat`.
“`{r problem8d}
#Enter your code here.
“`
e. Report the data values (should be 3 values) from the first row of your matrix of data values by using R code to print them. Report the mean and standard deviation of three data values by using R code to calculate these values. Use R as a calculator to calculate the test statistic for these three data values only. Then print the first element of the object `test.stat` to verify that it was calculated correctly. Be ware of order of operations – PEMDAS!
“`{r problem8e}
#Enter your code here.
“`
9. We can use the following code to calculate the two-sided p-value:
Note that the `abs()` function in R calculates absolute values. I did this because I wanted to only work with the positive version of the test statistics. Since the t-distribution is symmetric, I can use mirror images to calculate p-values more efficiently. Additionally, I can multiple by 2 in order to find the two-sided p-value. Complete the two blanks in the code and run it below. Your outcome should be a vector with one p-value for each row of the data. Print your vector pvals also.
“`{r problem9}
#Enter your code here.
“`
10. Find the proportion of times the p-values were less than 0.05. Note that you should use a logical comparison to get TRUE/FALSE values for each p-value based on if it is less than 0.05. Then fill in the blanks in the two interpretations below.
“`{r problem10}
#Enter your code here.
“`
We can interpret the proportion or percentage from your calculated from the previous problem as follows:
Interpretation 1: ___% of the time we correctly rejected the null hypothesis that $H_0: \mu = 107$ when the true population mean is $\mu = 100$ based on samples of size 3.
OR
Interpretation 2: The probability of correctly rejecting the null hypothesis of $H_0: \mu = 107$ when the true population mean is $\mu = 100$ is about ___ based on samples of size 3.
###The remaining problems ask you to re-run your code from #2-10 making changes each time. Copy and paste your code and re-run it to answer the following questions. Do not edit your original code (so that I can grade questions #2-10). Instead, copy and paste all of the individual lines of code from #2-#10 and make the necessary changes. HOWEVER, REMOVE ANY PRINTING OF OBJECTS. I DON’T WANT TO SEE ANYTHING THAT IS 1000 LINES LONG!
11. Our answer in #10 was based on seeing the process repeated a mere 10 times. That’s not enough to see the long-term patterns! Copy your code from #2-10 and paste it below. **Remove any lines of code that would print out objects.** For this problem, I want you to change the number of `rows` to 1000 so that we can look at the long-term proportion of times the null hypothesis is correctly rejected. Your code should ultimately print out the proportion of times you obtained a p-value of less than 0.05 and therefore rejected the null hypothesis. Also, write a sentence to summarize the proportion you find in context as indicated in the space after your R code.
“`{r problem11}
#Enter your code here.
Statistical Computing Assignment Paper
Type your sentence in plain text here:
12. Our answer in #10 was based on seeing the process repeated a mere 10 times but it was also based on samples of size 3. That’s not very interesting! Copy your code from #11. For this problem, I want you to change the number of `rows` to 1000 and to change the `samplesize` to 30 so that we can look at the long-term proportion of times the null hypothesis is correctly rejected for a larger sample size. Your code should ultimately print out the proportion or times you obtained a p-value of less than 0.05 and therefore rejected the null hypothesis. Type your code below. Also, write a sentence to summarize the proportion you find in context as indicated in the space after your R code and answer the questions that follow by typing in plain text.
“`{r problem12}
#Enter your code here.
“`
Type your sentence in plain text here:
Is this what you would expect? (YES/NO)
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
Explain. Type your answer as plain text here:
TYPE YOUR ANSWER HERE IN PLAIN TEXT:
We can write this or a similar paper for you! Simply fill the order form!
Important Role of Statistics in Driving Modern World There are three kinds of lies: lies, damned lies, and statistics Do you know what Mark Twain said about statistics?
Important Role of Statistics in Driving Modern World
In his autobiography, he once wrote: “There are three kinds of lies: lies, damned lies and statistics.”
On two-three pages , write an essay (double spaced) that explains the important role statistics plays in driving the modern world. How does statistics help managers assess the credibility and usefulness of information? How can it help them make decisions that lead to the most optimal outcomes? Please address these questions in your essay.
You are encouraged to be as creative as possible; for example, you may use well-known quotes, that are contrary to the Twain quote above, to support your points. Humorous references are welcome, as well. Just be sure to include all of your references used at the end of your essay.
It is assumed that you had installed Eviews on your computer.
How to Download Eviews and Statistical Analysis
The intention of this assignment is to teach you how to download your data file into Eviews and do some statistical analysis.
Look at Eviews Help and the Help files so to know how to import data.
Go to Yahoo finance and obtain data (closing prices) on five companies for the past five years. Also, obtain data on the S&P500 or another index of your choice. You can organize your data initially in an Excel spreadsheet and then import that into Eviews.
How to Download Eviews and Statistical Analysis
Import the data from the Excel file so to create an Eviews workfile. Import only the closing prices on each stock.
Once created, use the Eviews workfile to generate the returns on each stock.
Compute all the statistical output on each of your series. Provide the sample mean, standard deviation, skewness, kurtosis and map the histogram of each return.
Comment on your output for each stock. I suggest also to create a group so you can do the analysis in groups using Eviews.
How to Download Eviews and Statistical Analysis
Pick any two series and run a regression of one variable on the other. Provide the statistical output from your regression and comment on each of them.
Now pick three series and run a regression of one variable on the other two. Again provide the statistical output from your regression and comment.
Can you estimate the beta on each stock by running the market model (Note that the market model is Comment on your results?
It is assumed that you had done Assignment #1 to carry the following steps.
The intention of this assignment is to teach you how to test the assumptions of the residuals.
Pick any two series and run a regression of one variable on the other. Provide the statistical output from your regression and comment on each of them.
Test the residuals for the heteroscedasticity using the white’s test. Make sure to explain how the test is conducted. Use the two versions: with and without cross products.
How to Download Eviews and Statistical Analysis
Test the residuals for the first order autocorrelation by using the Durbin-Watson test statistic. Provide an explanation on how the test can be done and your results.
Can you test for higher-order autocorrelations using the LM test. Look at Eviews (or the powerpoint slides) for how to conduct the test.
What about the normality assumption of the residuals. Provide the explanation and results from the Jarque-Bera test.
? Pick any stability of coefficients tests provided in Eviews. Then conduct the test on your regression. You are supposed to provide an explanation of this test and your results.
Now pick three series and run a regression of one variable on the other two. Again provide all the statistical tests on the residuals (i.e., heteroscedasticity, autocorrelation, normality and stability of coefficients).
This essay should be about logistic function and its application in predicting the infectious rate of different epidemic diseases.
It should involve lots of calculation steps and accurate math terminologies.
It would be better if the essay makes use of calculus (high school level differentiation and integration) and statistics.
The academic standard is IB mathematics HL (higher level).
Infectious rate of different epidemic diseases
What is your current aim and rationale with the project?
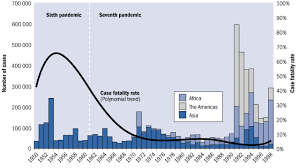
Recently, the outburst of Ebola in the west Africa has claimed more than 4,800 lives and this number is sure to rise. Other epidemic diseases around the world or in the history has affected the society or even the basis of civilization, such as the notorious Black Death, influenza, bird flu, SARS and HIV.
The essay aims to explore the speed of the infection of different diseases and see how factors such as technological advancement, mode of transmission, nature of the virus and locations affect the rate of infection. After a general formula of the infection rate is generated, these factors would be represented as mathematical constant in the equation.
Ideally, after comparing different epidemics, the essay would also propose a graph that plots he fatality ratio against the chronological order of history to see how development is hygiene and medical sciences has helped reducing the fatality and infection of different epidemics (though I am afraid the number of different epidemics that can be incorporated into this final graph would be limited because of time constraint, which may lead to an insufficient conclusion).
How will you use mathematics to achieve this? What mathematics will be used? Include specific topics you believe you believe will have to use in your exploration.
The epidemic model of infectious rate involves the appliance of various functions (exponential, logarithm and etc.) and potentially simple knowledge in statistics.
The actual interpretations of the statistics and the model built would largely rely on the knowledge of differentiation and integration, especially methodology introduced in 16.9 (differential equations)
What opportunities will there be for you to critically reflect on your work? Have other people attempted what you are trying to do? Make a note of these people here.
Limitation in statistics: It may be difficult to acquire accurate data of patients and death because identifying the disease needs time and there might be misjudgment in the early stage of diagnosing that some deaths would be attributed to other disease or vice versa.
Different diseases might have different ways of transmission, thus having different pattern of infection over time. If the essay fails to give a conclusion about the universal pattern of epidemics, reflection can be done
The statistics in terms of infection of the diseases should be available online from different resources. The modeling of infection rate has already been widely discussed and well established. Terminologies such as the basic reproductive rate (Ro) and fatality ratio would be useful in elucidating the concepts
How will you be able to demonstrate a significant amount of personal engagement with this topic? Is there an opportunity for you to use the mathematics you discover in a new or creative way? Can you extend your work to take into account other areas of mathematics?
Since the topic involves a lot of biology, I will have to read more about the background information of diseases as well as the contemporary medical condition. The actual process of using differentiation and integration for mathematic model is also new to me, so I will have to learn this portion of math by myself.
The data collected can be presented in a very creative way and thus knowledge in statistics can be applied to optimize the graphical representation.
Feedback/ Comments from Teacher:
We can write this or a similar paper for you! Simply fill the order form!
Only two questions, but professional knowledge required, for more details please check files below. (Notice: use your own and unique example to answer question 2, otherwise it’s not acceptable.)
Exercise Set 3
Wednesday, February 27
1. Four pirates have left on an island their treasure chests, with values 100, 200, 300 and 400.
One day the pirates learned that the volcano on the island will erupt soon and destroy their treasures. Unfortunately their ship was wrecked and they could not reach the island. A fisherman comes along on a raft and offers help. He says to the pirates: “My raft is small and I can only bring back one treasure chest from the island before the volcano erupts. Write the
value of your treasure chest on the palm of your hand and show it to me so no one else can see. I will retrieve the chest of the one who shows me the highest value. When I come back, the owner of the chest I bring back will pay me, and the payment will be equal to the second highest value that was shown to me.” (i) What value should each pirate write down on his hand? Is it better for him to lie or to tell the truth? (ii) When each pirate acts optimally,
whose chest will be brought back by the fisherman? How much payment will he receive?
*** The question below is a bonus points assignment. If you choose to do it, the due date is
Monday, March 4. We will ONLY accept a TYPED answer.
2. Think of a real life situation where you can apply the Vickrey mechanism to induce people to
reveal truthfully their hidden information. Clearly describe the problem. Explain how you will
implement the Vickrey mechanism, and why people will “tell the truth.”
We can write this or a similar paper for you! Simply fill the order form!
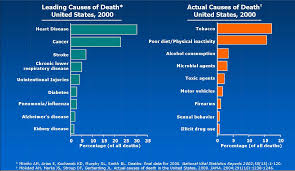
What are the top three causes of deaths in the United States?
What are Kuble-Ross’s 5 Stages Loss?
Your assignment must follow these formatting requirements:
Be typed, double spaced, using Times New Roman font (size 12), with one-inch margins on all sides; citations and references must follow APA or school-specific format. Check with your professor for any additional instructions.
Include a cover page containing the title of the assignment, the student’s name, the professor’s name, the course title, and the date. The cover page and the reference page are not included in the required assignment page length.
We can write this or a similar paper for you! Simply fill the order form!
Case Assignment
Part I: Identifying Constraints
Each short scenario describes a business situation. For each scenario, please write a short paragraph explaining which constraint or constraints is/are present, and why.
A taxi company limits its drivers to one eight-hour shift per day, with one half-hour break for a meal. A taxi cannot carry more than three passengers, all in the back seat, and cannot combine stops; that is, all the passengers must be going to the same destination.
Acme Unlimited sells custom machine tools. The sales department must send each order to Engineering for approval. There are no exceptions to this rule, which creates delays.
An online university offers six-week terms, with three two-week modules per term. Each module is supposedly limited to one topic, or set of related topics. Faculty members find it difficult to create interesting courses, and students express frustration with their learning experiences.
Part II: Describing Constraints
For each situation, write down the appropriate constraint. Please use the standard symbols “+” and “-” for plus and minus, and “ * ” for multiplication; however, if you find the symbols “≤” and “≥” difficult to keep straight, you may write “LE” for “Less than or equal to,” and “GE” for “Greater than or equal to.”
Example: An office is buying filing cabinets. The Model A cabinet holds a maximum of 3 cubic feet of files. Model B holds a maximum of 4.5 cubic feet of files. At any time, the office will have a maximum of 17 cubic feet of files that need to be stored. (A bit more cabinet space wouldn’t be a problem, but not enough would be. The files can’t be stacked on the floor.) Write a constraint on the number of cabinets the office should acquire.
Variables:
A = number of Model A cabinets purchased
B = number of Model B cabinets purchased
Answer:
A*( 3 cubic feet) + B*(4.5 cubic feet) ≥ 17 cubic feet
Or
A*( 3 cubic feet) + B*(4.5 cubic feet) GE 17 cubic feet
Patty makes pottery in her home studio. She works a total of six hours (360 minutes) per day. It takes her 10 minutes to make a cup, 15 minutes to make a bowl, and 30 minutes to make a vase. Write a constraint governing the joint production of cups, bowls and vases in a day. (Trans: “joint” = determined together; each affected by the others.)
Variables:
C = number of cups made
B = number of bowls made
V = number of vases made
An aid agency is buying generators for storm survivors. The generators will be shipped on a convoy of flatbed trucks having a total usable cargo area of 1,350 square feet. Generator A has a footprint (floor space required) of 8 square feet, and Generator B has a footprint of 12 square feet. Write a constraint governing the number of generators of each type than can be shipped.
Variables:
GenA = number of type A generators shipped
GenB= number of type B generators shipped
3. Patty (see 2.1. above) earns the following profit on each product:
Vase: $1.35
Cup: $0.75
Bowl: $2.40
Using the variable labels given in 2.1, write the profit equation for one of Patty’s days.
Part III: Solving an Allocation Problem
A small Excel application, LP Estimation.xlsx is available to help you with this part of the Case.
A refinery produces gasoline and fuel oil under the following constraints.
Let
gas = number of gallons of gasoline produced per day
fuel = number of gallons of fuel oil produced per day
Demand constraints:
Minimum daily demand for fuel oil = 3 million gallons (fuel ≥ 3)
Maximum daily demand for gasoline = 6.4 million gallons (gas ≤ 6.4)
Production constraints:
Refining one gallon of fuel oil produces at least 0.5 gallons of gasoline.
(fuel ≤ 0.5*gas; gas ≥ 2 fuel
Wholesale prices (earned by the refinery):
Gas: $1.90 per gallon
Fuel oil: $1.5 per gallon.
Your job is to maximize the refinery’s daily profit by determining the optimum mix of fuel oil and gasoline that should be produced. The correct answer consists of a number for fuel oil, and a number for gasoline, that maximizes the following profit equation:
P = (1.90)*gas + (1.5)*fuel (Answer will be in millions of dollars.)
Run at least 10 trials, and enter the data into a table that should look something like this:
Trial production values:
Profit:
Fuel oil
Gasoline
3.1
6.3
16.62
Etc.
Here’s how the “LP Estimation” worksheet is set up:
The tentative production goals are between the allowable minimum and maximum for each. Note that the maximum fuel oil that can be produced depends upon the gas production. Conversely, the minimum gas that can be produced depends upon the fuel oil production. If you don’t use the worksheet, the challenge will be to find test values for both oil and gas production that jointly satisfy the constraints.
Note: This is NOT how such a problem is usually solved. Rather, it is solved using LP. The purpose of this exercise is to acquaint you with the type of problem that’s usually solved using LP, and give you an appreciation of how difficult such a problem would be without LP.
Assignment Expectations
There are no page limits. Write what you need to write, neither more nor less. Make each sentence count! (Having said that; it’s unlikely that one page would be enough, and very likely that eight pages would be too much.)
Ensure that your answer reflects your detailed understanding of the theory and techniques taught in this module.
References and citations are required. This requirement can be satisfied by citing the module Home page.
Follow the instructions in the Writing Style Guide.
We can write this or a similar paper for you! Simply fill the order form!
3. Click over to Variable View
4. Name each variable (do not put spaces)
5. Label each variable
6. Assign a measure
a. Nominal
i. This is for things like names, store, gender, type of student, etc.
b. Scale
i. This is for weight, annual sales, square footage, things on a scale
9. Select OK
10. Data will be put in the output screen
Model Summary
Model
R
R Square
Adjusted R Square
Std. Error of the Estimate
1
.954a
.910
.893
978.44654
a. Predictors: (Constant), Square Footage, Number of Employees
ANOVAa
Model
Sum of Squares
df
Mean Square
F
Sig.
1
Regression
106209441.045
2
53104720.522
55.470
.000b
Residual
10530933.884
11
957357.626
Total
116740374.929
13
a. Dependent Variable: AnnualSales
b. Predictors: (Constant), Square Footage, Number of Employees
Coefficientsa
Model
Unstandardized Coefficients
Standardized Coefficients
t
Sig.
11. Write up the analysis
​a. Define the dependent variable and the predictor (independent variable).
​b. Discuss the test used (Multiple Regression)
c. R2 = .91 which means that 91% of annual sales is being predicted by BOTH the number of employees and square footage
d. F (df) = ________ , p ________ will tell us whether or not the multiple regression used to determine if the predictors affect the dependent variables was significant
​i. F (2,13) = 55.47, p < .001 tells us that the multiple regression was significant
e. Now we have to examine both predictors to determine their significance: Number of Employees and Square Footage
​i. Use t(Total) = _________ , p ________ for each predictor
Number of employees: t(13) = .04, p = .97 Ã not sig. because p is above .05
Square footage: t(13) = 9.88, p < .001 Ã sig. because p is below .05
f. The write-up must include the discussion about R2, whether or not the multiple regression test used was significant (F (df) = _________, p ______) and if the predictors were significant using t(Total) = ______ , p ______.
We can write this or a similar paper for you! Simply fill the order form!